Before asking a question, it's a good habit to describe your intention clearly. Below is a real story happened between me and a coworker.
CW: hey, do you know how to do B on windows?
ME: o, yes. You can:
1. Blah blah
2. Blah blah
3. Blah blah
But why you want to do this?
CW: hmmm, because I want to do A.
ME: Do A? Why ask B? They're not related.
CW: Why? According to concept C, A is controlled by B.
ME: No, you misunderstood concept C. It's blah blah
CW: O, i see.
If he asked how to do A at the beginning, we both can save a lot of time.
When we need to ask a question, it's a sign that we don't understand the stuff very well. Then we'd better describe our intention directly. If we ask a different topic by our own deduction, which may be a misunderstanding, we may be on the wrong track.
Monday, April 26, 2010
Sunday, April 25, 2010
streaming audio on android
Streaming media refers to the capability of playing media data while the data is being transferred from server. The user doesn't need to wait until full media content has been downloaded to start playing. In media streaming, media content is split into small chunks as the transport unit. After the user's player has received sufficient chunks, it starts playing.
From the developer's perspective, media streaming is comprised of two tasks, transfer data and render data. Application developers usually concentrate more on transfer data than render data, because codec and media renderer are often available already.
On android, streaming audio is somewhat easier than video for android provides a more friendly api to render audio data in small chunks. No matter what is our transfer mechanism, rtp, raw udp or raw file reading, we need to feed chunks we received to renderer. The AudioTrack.write function enables us doing so.
AudioTrack object runs in two modes, static or stream. In static mode, we write the whole audio file to audio hardware. In stream mode, audio data are written in small chunks. The static mode is more efficient because it doesn't have the overhead of copying data from java layer to native layer, but it's not suitable if the audio file is too big to fit it memory. It's important to notice that we call play at different time in two modes. In static mode, we must call write first, then call play. Otherwise, the AudioTrack raises an exception complains that AudioTrack object isn't properly initialized. In stream mode, they are called in reverse order. Under the hood, static and stream mode determine the memory model. In static mode, audio data are passed to renderer via shared memory. Thus static mode is more efficient.
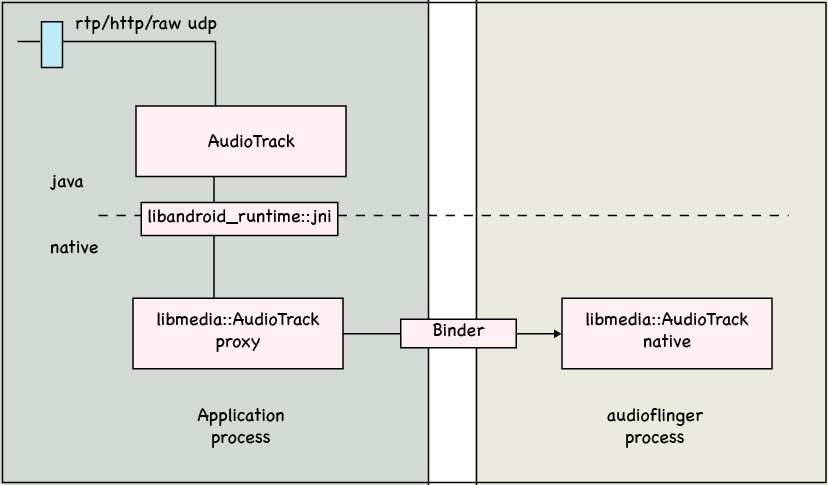
From birds eye view, the architecture of an typical audio streaming application is:
 Our application receives data from network. Then the data will be passed to a java layer AudioTrack object which internally calls through jni to native AudioTrack object. The native AudioTrack object in our application is a proxy that refers to the implementation AudioTrack object resides in audioflinger process, through binder ipc mechanism. The audiofinger process will interact with audio hardware.
Our application receives data from network. Then the data will be passed to a java layer AudioTrack object which internally calls through jni to native AudioTrack object. The native AudioTrack object in our application is a proxy that refers to the implementation AudioTrack object resides in audioflinger process, through binder ipc mechanism. The audiofinger process will interact with audio hardware.
Since our application and audioflinger are separate processes, so after our application has written data to audioflinger, the playback will not stop even if our application exits.
AudioTrack only supports PCM (a.k.a G.711) audio format. In other words, we can't stream mp3 audio directly. We have to deal with decoding ourselves, and feed decoded data to AudioTrack.
Sample
http://code.google.com/p/rxwen-blog-stuff/source/browse/trunk/android/streaming_audio/
For demonstration purpose, this sample chooses a very simple transfer mechanism. It reads data from a wav file on disk in chunks, but we can consider it as if the data were delivered from a media server on network. The idea is similar.
Update: Check this post for a more concrete example.
From the developer's perspective, media streaming is comprised of two tasks, transfer data and render data. Application developers usually concentrate more on transfer data than render data, because codec and media renderer are often available already.
On android, streaming audio is somewhat easier than video for android provides a more friendly api to render audio data in small chunks. No matter what is our transfer mechanism, rtp, raw udp or raw file reading, we need to feed chunks we received to renderer. The AudioTrack.write function enables us doing so.
AudioTrack object runs in two modes, static or stream. In static mode, we write the whole audio file to audio hardware. In stream mode, audio data are written in small chunks. The static mode is more efficient because it doesn't have the overhead of copying data from java layer to native layer, but it's not suitable if the audio file is too big to fit it memory. It's important to notice that we call play at different time in two modes. In static mode, we must call write first, then call play. Otherwise, the AudioTrack raises an exception complains that AudioTrack object isn't properly initialized. In stream mode, they are called in reverse order. Under the hood, static and stream mode determine the memory model. In static mode, audio data are passed to renderer via shared memory. Thus static mode is more efficient.
From birds eye view, the architecture of an typical audio streaming application is:
Since our application and audioflinger are separate processes, so after our application has written data to audioflinger, the playback will not stop even if our application exits.
AudioTrack only supports PCM (a.k.a G.711) audio format. In other words, we can't stream mp3 audio directly. We have to deal with decoding ourselves, and feed decoded data to AudioTrack.
Sample
http://code.google.com/p/rxwen-blog-stuff/source/browse/trunk/android/streaming_audio/
For demonstration purpose, this sample chooses a very simple transfer mechanism. It reads data from a wav file on disk in chunks, but we can consider it as if the data were delivered from a media server on network. The idea is similar.
Update: Check this post for a more concrete example.
Saturday, April 24, 2010
why I prefer wireshark to network monitor
Personally, I prefer wireshark to network monitor for:
But network monitor has the advantage of being able to categorize network messages by processes. As shown in the image below:

It's a very convenient feature that helps me easily find out messages I'm interested in. Especially when I need to debug a process whose port numbers are picked at random or dynamically.
- Wireshark runs on many platforms including windows, linux, mac os x, etc. I need to work both on linux and windows, and I'd like to keep my toolbox as compact as possible.
- Wireshark uses a widely adopted syntax for capture filters and disply filters which dare I call them de facto. The same syntax is used in windump and tcpdump. I don't need to remember additional syntax even work in a GUI-less environment.
- Filters in wireshark seems to be more powerful. For example, the filter "tcp.flags.syn==1" enables me to view tcp SYN messages only. Based on my limited experience with network monitor, I'm not aware if it can filter at this granularity.
But network monitor has the advantage of being able to categorize network messages by processes. As shown in the image below:
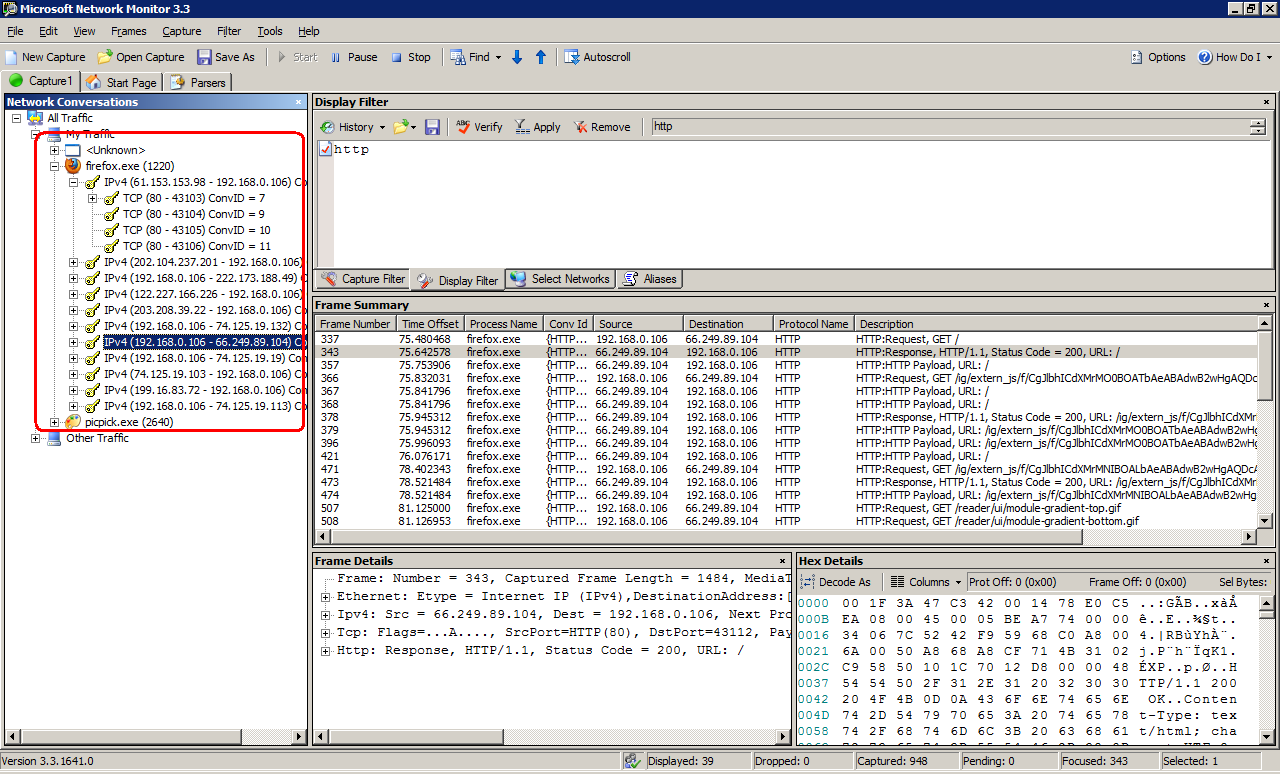
It's a very convenient feature that helps me easily find out messages I'm interested in. Especially when I need to debug a process whose port numbers are picked at random or dynamically.
Friday, April 23, 2010
standalone windbg v6.12.0002.633
I read from Tomas's post that newer version windbg can't be downloaded from microsoft directly anymore. To get newer windbg, we have to download the huge 620 mb WDK iso and extract windbg installer from it manually. The newest windbg standalone installer is version 6.11.1.404, released on March 27, 2009.
I don't know if microsoft will listen to our customer's voice and release a standalone windbg. Before they will, for the convenience for developers like me, here is extracted windbg package:
windbg 6.12.0002.633 x86 http://rxwen-blog-stuff.googlecode.com/files/windbg_6.12.0002.633_x86.zip
md5sum: abdad1a805f7d89d461b4569b216001d
sha1sum: 3715d726363524643a6df561bf9d27e7acb49307
windbg_6.12.0002.633_64_installer http://rxwen-blog-stuff.googlecode.com/files/windbg_6.12.0002.633_64_installer.zip
md5sum: 62fc3d313081f96fea3f69c4d06700a1
sha1sum: d79e6f40c08a95d5653c0eb0cc7d64c8bea8e391
A noticable change of this version is: ADPlus V7.0 is a total rewrite of ADPlus. ADPlus is now written in managed code which will allow us to add new features much easier. The old version is renamed to adplus_old.vbs. This page lists more changes of the new version.
Hope it helps.
I don't know if microsoft will listen to our customer's voice and release a standalone windbg. Before they will, for the convenience for developers like me, here is extracted windbg package:
windbg 6.12.0002.633 x86 http://rxwen-blog-stuff.googlecode.com/files/windbg_6.12.0002.633_x86.zip
md5sum: abdad1a805f7d89d461b4569b216001d
sha1sum: 3715d726363524643a6df561bf9d27e7acb49307
windbg_6.12.0002.633_64_installer http://rxwen-blog-stuff.googlecode.com/files/windbg_6.12.0002.633_64_installer.zip
md5sum: 62fc3d313081f96fea3f69c4d06700a1
sha1sum: d79e6f40c08a95d5653c0eb0cc7d64c8bea8e391
A noticable change of this version is: ADPlus V7.0 is a total rewrite of ADPlus. ADPlus is now written in managed code which will allow us to add new features much easier. The old version is renamed to adplus_old.vbs. This page lists more changes of the new version.
Hope it helps.
Wednesday, April 21, 2010
Use google.com instead of google.com.hk
After google moved their service from china mainland to hongkong, I can't access google.com or google.cn from mainland anymore. I always get redirected to google.com.hk. Based off my experience with google.com.hk, it shows more noise information than google.com and google.cn. Because in most cases, results in transitional chinese aren't what I'm looking for.
To force the browser using google.com, we can visit the url http://www.google.com/ncr. After it has been visited once, all subsequent requests for google.com won't be redirected to google.com.hk anymore. Hooray!
To force the browser using google.com, we can visit the url http://www.google.com/ncr. After it has been visited once, all subsequent requests for google.com won't be redirected to google.com.hk anymore. Hooray!
Sunday, April 18, 2010
Override CheckMediaType with care
A problem I encountered while developing my source filter's output pin is that inside FillBuffer method, the media type and size of the media sample is not exactly the same as the one I proposed in GetMediaType method. The strange thing is my pin has successfully negotiated with downstream renderer filter (its actual type is Video Mixing Renderer-9 filter), and its input pin has agreed to use the media type my filter proposed. So why the actual media type being used changes?
The answer lies in this document, handling format changes from the video renderer:
Video Mixing Renderer Filter
The Video Mixing Renderer filter (VMR-7 and VMR-9) will connect with any format that is supported by the graphics hardware on the system. The VMR-7 always uses DirectDraw for rendering, and allocates the underlying DirectDraw surfaces when the upstream filter connects. The VMR-9 always uses Direct3D for rendering, and allocates the underlying Direct3D surfaces when the upstream filter connects.
The graphics hardware may require a larger surface stride than the image width. In that case, the VMR requests a new format by calling QueryAccept. It reports the surface stride in the biWidth member of the BITMAPINFOHEADER in the video format. If the upstream filter does not return S_OK from QueryAccept, the VMR rejects the format and tries to connect using the next format advertised by the upstream filter. The VMR attaches the media type with the new format to the first media sample. After the first sample, the format remains constant; the VMR will not switch formats while the graph is running.
During the connecting phase, after both filters' pins have agreed on a media type, they perform allocator negotiation. And the downstream pin proposed a larger biWidth during allocator negotiation. As a result to the new proposal, our pin's QueryAccept method is called. If we don't override it, the default implementation of grandpa class CBasePin comes into play. CBasePin::QueryAccept internally calls CheckMediaType method to see if the newly proposed media type can be accepted. Because our pin's CheckMediaType method's original implementation is too sloppy without examining all fields of the new media type, so we ended in the situation I described at the beginning of the post.
So, the best practice for creating a source filter is we need to handle CheckMediaType carefully. Or we can take the alternative way of overriding the QueryAccept method to handle media type change explicitly.
References:
How to Write a Source Filter for DirectShow
Core Media Technology in Windows XP Empowers You to Create Custom Audio/Video Processing Components
The answer lies in this document, handling format changes from the video renderer:
Video Mixing Renderer Filter
The Video Mixing Renderer filter (VMR-7 and VMR-9) will connect with any format that is supported by the graphics hardware on the system. The VMR-7 always uses DirectDraw for rendering, and allocates the underlying DirectDraw surfaces when the upstream filter connects. The VMR-9 always uses Direct3D for rendering, and allocates the underlying Direct3D surfaces when the upstream filter connects.
The graphics hardware may require a larger surface stride than the image width. In that case, the VMR requests a new format by calling QueryAccept. It reports the surface stride in the biWidth member of the BITMAPINFOHEADER in the video format. If the upstream filter does not return S_OK from QueryAccept, the VMR rejects the format and tries to connect using the next format advertised by the upstream filter. The VMR attaches the media type with the new format to the first media sample. After the first sample, the format remains constant; the VMR will not switch formats while the graph is running.
During the connecting phase, after both filters' pins have agreed on a media type, they perform allocator negotiation. And the downstream pin proposed a larger biWidth during allocator negotiation. As a result to the new proposal, our pin's QueryAccept method is called. If we don't override it, the default implementation of grandpa class CBasePin comes into play. CBasePin::QueryAccept internally calls CheckMediaType method to see if the newly proposed media type can be accepted. Because our pin's CheckMediaType method's original implementation is too sloppy without examining all fields of the new media type, so we ended in the situation I described at the beginning of the post.
So, the best practice for creating a source filter is we need to handle CheckMediaType carefully. Or we can take the alternative way of overriding the QueryAccept method to handle media type change explicitly.
References:
How to Write a Source Filter for DirectShow
Core Media Technology in Windows XP Empowers You to Create Custom Audio/Video Processing Components
Sunday, April 11, 2010
Thoughts on directshow
In this post, I'll summarize some features that make directshow stand out, from a developer's point of view.
The architecture of directshow is:

The core of directshow framework is the box in the center.
1. separation of concerns
Directshow divides a complex media rendering task into a bunch of smaller tasks, organized as different filters. Each filter has its own concentration, e.g., grabbing data from source media file, decoding data, rendering the data on display. It's more natural and easier for our brain to resolve complex problems in smaller steps, one by one. Another benefit of this breakdown structure is we can perform unit test on smaller component more easily.
2. mature abstraction layer
Directshow provides a mature abstraction layer on top of sub-tasks' concrete implementations (Adapter pattern). The existence of the abstraction layer makes our project easier to manage. The cost for dealing with changes can be minimized. For example, we can have one guy tries to implement a hardware based decoder filter. And before his filter is available, other guys in charge of other parts can use a software based decoder filter instead. After the hardware based filter is done, it's hopeful to replace the software based filter without requiring changes on other parts because interfaces of both filters are the same.
3. built-in multimedia functions
Besides being a sophisticated core framework, directshow also contains a lot of commonly used multimedia features like common media type decoders, some splitters, and multi-stream synchronizer. With these features built-in, we developers' life will be a lot easier.
References
MSDN: Directshow System Overview
http://en.wikipedia.org/wiki/DirectShow
The architecture of directshow is:

The core of directshow framework is the box in the center.
1. separation of concerns
Directshow divides a complex media rendering task into a bunch of smaller tasks, organized as different filters. Each filter has its own concentration, e.g., grabbing data from source media file, decoding data, rendering the data on display. It's more natural and easier for our brain to resolve complex problems in smaller steps, one by one. Another benefit of this breakdown structure is we can perform unit test on smaller component more easily.
2. mature abstraction layer
Directshow provides a mature abstraction layer on top of sub-tasks' concrete implementations (Adapter pattern). The existence of the abstraction layer makes our project easier to manage. The cost for dealing with changes can be minimized. For example, we can have one guy tries to implement a hardware based decoder filter. And before his filter is available, other guys in charge of other parts can use a software based decoder filter instead. After the hardware based filter is done, it's hopeful to replace the software based filter without requiring changes on other parts because interfaces of both filters are the same.
3. built-in multimedia functions
Besides being a sophisticated core framework, directshow also contains a lot of commonly used multimedia features like common media type decoders, some splitters, and multi-stream synchronizer. With these features built-in, we developers' life will be a lot easier.
References
MSDN: Directshow System Overview
http://en.wikipedia.org/wiki/DirectShow
Saturday, April 3, 2010
directshow debugging tips
1. View graph

When we render a media file, directshow uses intelligent connect to build a working graph for us. It may add some filters implicitly if necessary. From my perspective, it all happens transparently. It's user friendly and powerful. But while debugging, we need to know exactly how is the graph constructed and connected, at runtime. Directshow provided a utility method AddGraphToRot in %WINSDK%\Samples\multimedia\directshow\common\dshowutil.h. We can use it to register our graph to running object table, and then view the graph in graphedit. After the graph has been registered, we select File - Connect to Remote Graph in graphedit to bring up remote filter graph list. Then select the registered graph to view.


2. Keep log
IGraphBuilder exposes a SetLogFile method that can be used to specify a log file. Once set, all of the graph's activities will be saved to the log file, including how filter's are connected, how the graph attempted to connect pins. These information are valuable for debugging filters.
pGraph->SetLogFile((DWORD_PTR)CreateFile(TEXT("C:\\graph_builder.log"), GENERIC_WRITE, 0, NULL, CREATE_NEW, FILE_ATTRIBUTE_NORMAL, NULL));
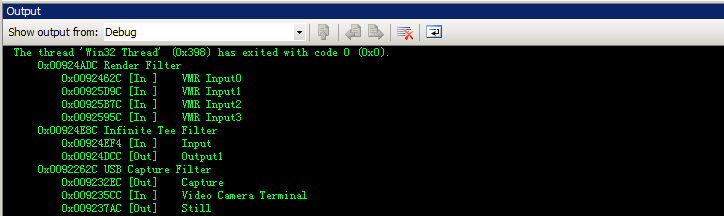
3. Dump graph
In the log file generated by graph, components (filter and pin) are identified with their address in memory. The friendly name of the component isn't shown which make the log file harder to understand by human. Here is a small utility function that dumps all filters and their pins with corresponding memory address and name, in the format shown below.
Subscribe to:
Posts (Atom)