libevent is usually used as substitution for
select system call to write efficient and portable code. A benefit of libevent is, besides normal fd, it enables monitoring signal, timeout and user supplied event in a
consistent manner.
Typically, the code makes use of libevent has the below structure:
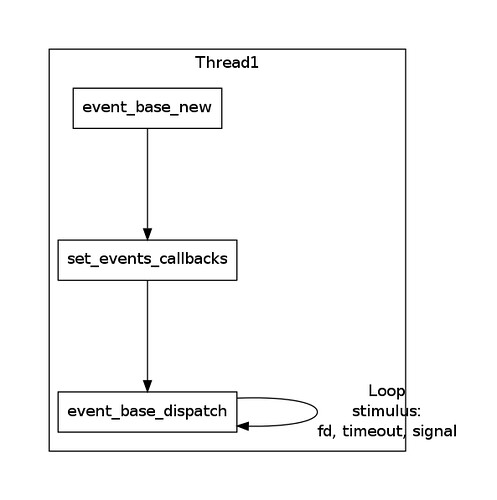
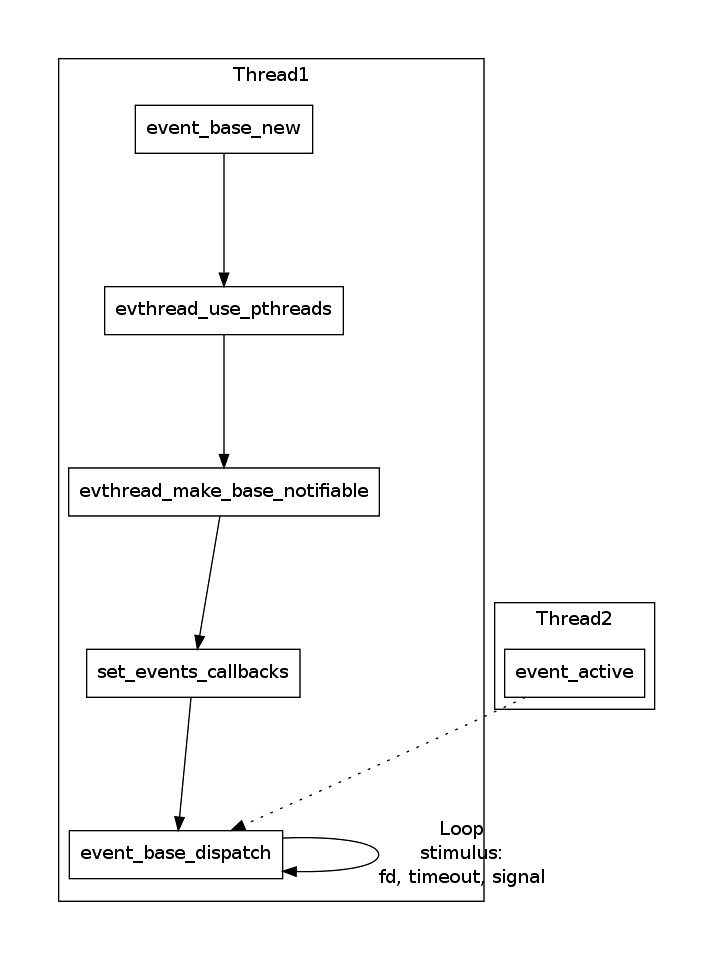
In the final step, we call
event_base_dispatch function which will run a loop on current thread until there is no more events to handle. Since the thread is busy running the loop, if we want to active an user event, we must do it in a new thread. We should notice that in libevent, we must explicitly set threading support via the
evthread_use_pthreads or
evthread_use_windows_threads, and we should call
evthread_make_base_notifiable function so that event_base can be notified by events on another thread. So, in order to use user event, we need to following things:
- Create an event struct for user event, and add it to the event_base
- Prepare threading for event_base by calling evthread_use_pthreads/evthread_use_windows_threads and evthread_make_base_notifiable
- Start a new thread, and monitor if the user event should be fired
- Call event_active on the user event if the firing condition has been satisfied
The structure is shown below:
And here is sample code.
1 /*
2 This exmple program provides a trivial server program that listens for TCP
3 connections on port 9995. When they arrive, it writes a short message to
4 each client connection, and closes each connection once it is flushed.
5
6 Where possible, it exits cleanly in response to a SIGINT (ctrl-c).
7 */
8
9
10 #include <string.h>
11 #include <errno.h>
12 #include <stdio.h>
13 #include <signal.h>
14 #ifndef _WIN32
15 #include <netinet/in.h>
16 # ifdef _XOPEN_SOURCE_EXTENDED
17 # include <arpa/inet.h>
18 # endif
19 #include <sys/socket.h>
20 #endif
21 #include <pthread.h>
22
23 #include <event2/bufferevent.h>
24 #include <event2/buffer.h>
25 #include <event2/listener.h>
26 #include <event2/util.h>
27 #include <event2/event.h>
28 #include <event2/thread.h>
29
30 static const char MESSAGE[] = "Hello, World!\n";
31
32 static const int PORT = 9995;
33
34 static void listener_cb(struct evconnlistener *, evutil_socket_t,
35 struct sockaddr *, int socklen, void *);
36 static void conn_readcb(struct bufferevent *, void *);
37 static void conn_writecb(struct bufferevent *, void *);
38 static void conn_eventcb(struct bufferevent *, short, void *);
39 static void signal_cb(evutil_socket_t, short, void *);
40
41 static struct event* init_user_event(struct event_base*);
42 static void* user_event_proc(void*);
43
44 int main(int argc, char **argv) {
45 struct event_base *base;
46 struct evconnlistener *listener;
47 struct event *signal_event, *user_event;
48 pthread_t th;
49
50 struct sockaddr_in sin;
51 int rc = 0;
52 #ifdef _WIN32
53 WSADATA wsa_data;
54 WSAStartup(0x0201, &wsa_data);
55 #endif
56
57 base = event_base_new();
58 if (!base) {
59 fprintf(stderr, "Could not initialize libevent!\n");
60 return 1;
61 }
62
63 evthread_use_pthreads();
64 if (evthread_make_base_notifiable(base)<0) {
65 printf("Couldn't make base notifiable!");
66 return 1;
67 }
68 memset(&sin, 0, sizeof(sin));
69 sin.sin_family = AF_INET;
70 sin.sin_port = htons(PORT);
71
72 listener = evconnlistener_new_bind(base, listener_cb, (void *)base,
73 LEV_OPT_REUSEABLE|LEV_OPT_CLOSE_ON_FREE, -1,
74 (struct sockaddr*)&sin,
75 sizeof(sin));
76
77 if (!listener) {
78 fprintf(stderr, "Could not create a listener!\n");
79 return 1;
80 }
81
82 signal_event = evsignal_new(base, SIGINT, signal_cb, (void *)base);
83
84 if (!signal_event || event_add(signal_event, NULL)<0) {
85 fprintf(stderr, "Could not create/add a signal event!\n");
86 return 1;
87 }
88 user_event = init_user_event(base);
89 pthread_create(&th, NULL, user_event_proc, user_event);
90
91 /*rc = event_base_loop(base, EVLOOP_NO_EXIT_ON_EMPTY);*/
92 event_base_dispatch(base);
93
94 evconnlistener_free(listener);
95 event_free(signal_event);
96 event_free(user_event);
97 event_base_free(base);
98
99 printf("done\n");
100 return 0;
101 }
102
103 static void listener_cb(struct evconnlistener *listener, evutil_socket_t fd,
104 struct sockaddr *sa, int socklen, void *user_data) {
105 struct event_base *base = (struct event_base*)user_data;
106 struct bufferevent *bev;
107
108 bev = bufferevent_socket_new(base, fd, BEV_OPT_CLOSE_ON_FREE);
109 if (!bev) {
110 fprintf(stderr, "Error constructing bufferevent!");
111 event_base_loopbreak(base);
112 return;
113 }
114 bufferevent_setcb(bev, conn_readcb, conn_writecb, conn_eventcb, NULL);
115 bufferevent_enable(bev, EV_WRITE);
116 bufferevent_enable(bev, EV_READ);
117
118 /*bufferevent_write(bev, MESSAGE, strlen(MESSAGE));*/
119 }
120
121 static void conn_readcb(struct bufferevent *bev, void *) {
122 struct evbuffer *input = bufferevent_get_input(bev);
123 printf("readcb\n");
124 int len = evbuffer_get_length(input);
125 if (len != 0) {
126 printf("readcb parse_message\n");
127 char* buf = new char[len]();
128 evbuffer_copyout(input, buf, len);
129 delete[] buf;
130 }
131 bufferevent_write(bev, MESSAGE, strlen(MESSAGE));
132 }
133
134 static void conn_writecb(struct bufferevent *bev, void *user_data) {
135 struct evbuffer *output = bufferevent_get_output(bev);
136 if (evbuffer_get_length(output) == 0) {
137 printf("flushed answer\n");
138 /*bufferevent_free(bev);*/
139 }
140 }
141
142 static void conn_eventcb(struct bufferevent *bev, short events, void *user_data) {
143 if (events & BEV_EVENT_EOF) {
144 printf("Connection closed.\n");
145 } else if (events & BEV_EVENT_ERROR) {
146 printf("Got an error on the connection: %s\n",
147 strerror(errno));/*XXX win32*/
148 }
149 /* None of the other events can happen here, since we haven't enabled
150 * timeouts */
151 bufferevent_free(bev);
152 }
153
154 static void signal_cb(evutil_socket_t sig, short events, void *user_data) {
155 struct event_base *base = (struct event_base*)user_data;
156 struct timeval delay = { 1, 0 };
157
158 printf("Caught an interrupt signal; exiting cleanly in one second.\n");
159
160 event_base_loopexit(base, &delay);
161 }
162
163 static void user_event_cb(evutil_socket_t, short events, void *user_data) {
164 printf("user event %04x fired!!!!!\n", events);
165 struct event_base *base = (struct event_base*)user_data;
166 /*event_base_dump_events(base, stdout);*/
167 }
168
169 static struct event* init_user_event(struct event_base* base) {
170 struct event *ev_user = NULL;
171 struct timeval timeout = { 2, 0 };
172 ev_user = event_new(base, -1, EV_TIMEOUT|EV_READ, user_event_cb, base);
173 /*event_add(ev_user, &timeout);*/
174 return ev_user;
175 }
176
177 static void* user_event_proc(void* data) {
178 printf("start user event thread\n");
179 struct event *ev_user = (struct event*)data;
180 char buf[512] = {0};
181
182 while(1) {
183 fgets(buf, sizeof(buf), stdin);
184 printf("read %d bytes from stdio, now fire user event\n", 0);
185 event_active(ev_user, EV_READ|EV_WRITE, 1);
186 }
187 return NULL;
188 }