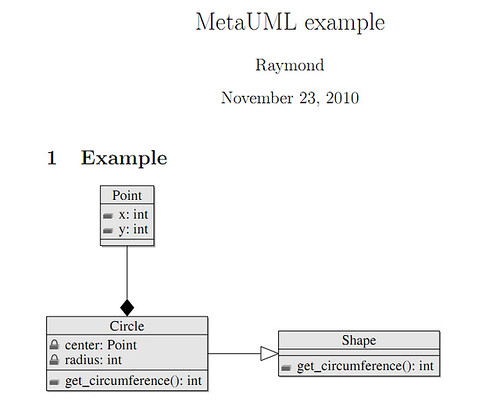
Having tried metauml as my primary design utility recently, the experience isn't as good as I expected. At the beginning, I thought I would be more focused on the content/design while using a pure textual editing tool, but the result is very frustrating. Because I have to pay more attention on the organization and layout, rather than the design. metauml doesn't help me organizing elements at all, leave it all to me. I have to think in advance where should an element be placed, and instructed metauml to place the element explicitly, either in absolute coordinate or in relative coordinate. It seems ok for simple diagrams with very few elements. But as the number of elements increases, it's very hard to plan in advance. Once I made a mistake, the cost to change it is huge, I may have to re-organize everything, to keep the diagram clean.
I found an graphical tool, bouml, as an great replacement. It's efficient and powerful. bouml saves everything in text, so it's also possible to do version control. The best feature I noticed so far is its capability of reversing c++ code. By feeding it with source code directories, it will generate a full list of classes, methods exist in the code. It's very helpful for analyzing others' projects.

It is very possible to run the Barnes and Noble Nook firmware in the Android Emulator. It is time to start developing some Google Android Apps for it.
Instructions for Unix/Linux
In order to do this, you will need to:
- Download the Android SDK and install it. Install the Platform 1.5 SDK using tools/android in the Android SDK.
- Grab the original 1.0.0 image from bn.com (mirrored here: multiupload).
- Run dd if=signed_bravo_update.1.0.0.dat of=signed-bravo-update.1.0.0.tar.gz bs=1 skip=152 (On Windows use this tool. At the command line run gzip-extract signed-bravo-update.1.0.0.tar.gz bravo_update.dat. NOTE: gzip-extract requires the .net framework. Afterwards rename bravo_update.dat to signed-bravo-update.1.0.0.tar.gz)
- Extract signed-bravo-update.1.0.0.tar.gz.
- Rename bravo_update.dat to bravo_update.tar.gz and extract it.
- Extract root.tgz.
- Extract root/system/framework/services.jar with your favorite unzip utility.
- Download and install smali. You need at least baksmali-1.1.jar and smali-1.1.jar. For your sanity, grab the wrapper scripts as well.
- Run baksmali classes.dex on the classes.dex from services.jar to disassemble services.jar
- Edit out/com/android/server/ServerThread.smali and remove the line if-lt v0, v1, :cond_483 This should be line 966. (In version 1.0.0)
- Run smali out/ to re-assemble classes.dex with our fixes.
- Rename out.dex to classes.dex and copy this classes.dex to services directory, overwriting the original classes.dex.
- Delete the out directory and re-jar the services directory.
- Make an Android Device (AVD entry) in the Android Emulator with target platform 1.5 and skin/screen size of 549 by 924 (real resolution is more like 600x944 but the emulator won't start at that size), name it nook (case sensitive).
- If you are unable to create the AVDs (something like Error: Ignoring platform 'google_apis-3-r03': build.prop is missing. ) then install Eclipse, install the Android plugins for Eclipse and you will be able to create the AVDs from there.
- grab lib/libaudioflinger.so from stock system.img supplied with Android SDK using unix utility unyaffs to extract the file
- overwrite the libaudioflinger.so from the system/lib directory in the nook firmware with the stock Android SDK one.
- use mkyaffs2image to make a system.img of the system/ of the nook firmware.
- rename system.img in the 1.5 firmware platform folder to system.good and copy in replacement system.img file you just created (it will be bigger than the SDK Android system.img (approximately 108Mb)
- Run the emulator by using command line emulator @nook -shell -show-kernel -verbose The emulator will take a few minutes to boot.
- You will NOT be able to register your emulated Nook with BN.com but you can sideload epub books but placing them in system/media/guides when you create your replacement system.img file mentioned in step 17.